看完NVIDIA GTC 2022感想
这篇个人感想纯胡说八道
吹牛是需要资本的,想在AI圈混迹,就得会吹AI的牛,不会?那就得和老黄学,所以GTC还是需要好好听的,听完可以吹牛。
- 老黄同志的皮衣不错,符合工程师的品味
- 倒是鞋子上的白色让人整体感觉年轻了一些
感慨NVIDIA在整个AI领域的布局,包括正经和不正经的,从机器视觉,语境分析,翻译,自动驾驶,生物医疗,工业机器人,全景地图,气候变化预测和作曲等等
就像Jensen同志说的那样:
AI is learning biology and chemistry, just as AI has learned images, sounds, and language
有几个我觉得NVIDIA是走在前列的:
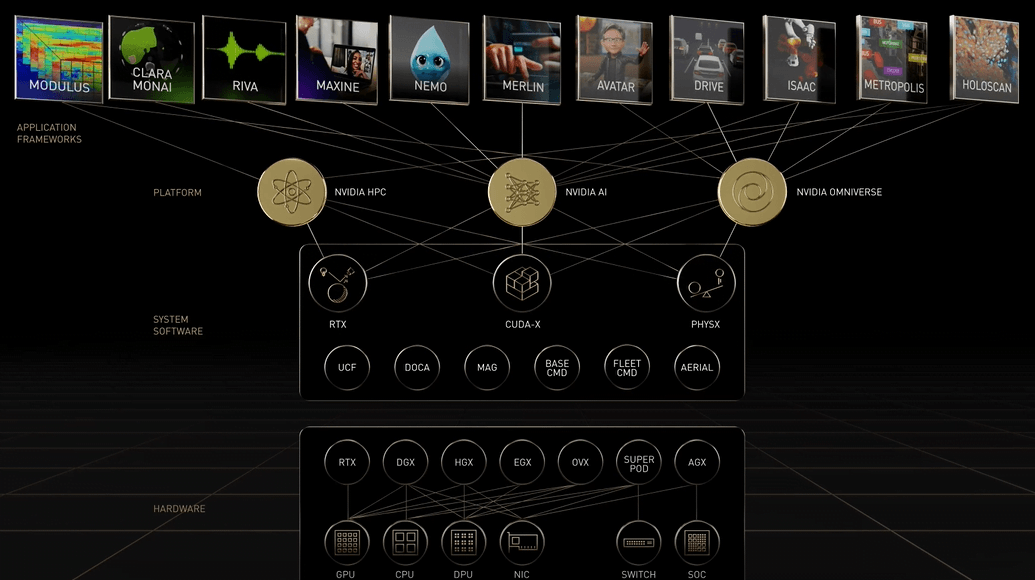
- AI计算,凭借着H100新GPU算力平台的发布,以及基于此的不同规模计算平台
- AI网络,凭借ConnectX系列网卡,Spectrum交换机
- AI平台,发布的包括Merlin,omniverse以及。。。
- Million-X
- Transformer
- AI Factory
- Robotics Systems
- Digital Twins
- Earth-2
英语学习时间
predict the 3D structure of the DNA from the amino acid sequence
从氨基酸序列来预测DNA的3D构架
CUDA libraries, NVIDIA SDK
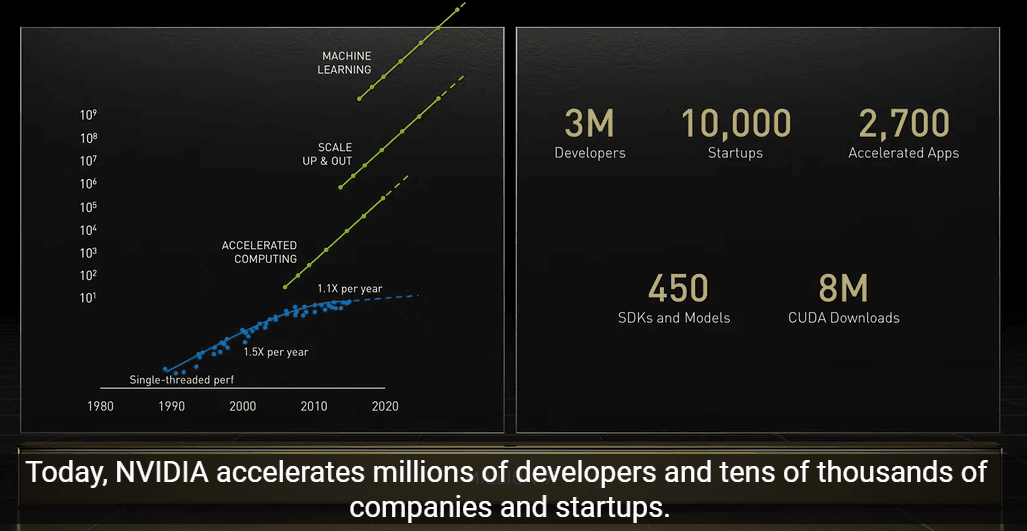
好多新东西值得了解的,看看AI科技是怎么改变世界的
NVIDIA is going to tackle this grand challenge with our Earth-2, the world’s first AI digital twin supercomputer
Researchers at NVIDIA, Caltech, Berkeley lab, Purdue, Michigan, and Rice Universities have developed a weather forecasting AI model called FourCastNet.
FourCastNet is a physics-informed deep learning model that can predict weather events such as hurricanes, asmospheric rivers, and extreme rain.
Atmospheric rivers are enormous rivers of water vapor in the sky – each carrying more water than the Amazon.

They provides a key source of precipitation for the western U.S., but these large, powerful storms can also cause catastrophic flooding and massive snowfalls.
Powered by the Fourier Neural Operator, this GPU-accelerated AI-enabled digital twin, called FourCastNet, is trained on 10TB of Earth system data.


这个变形金刚是什么?
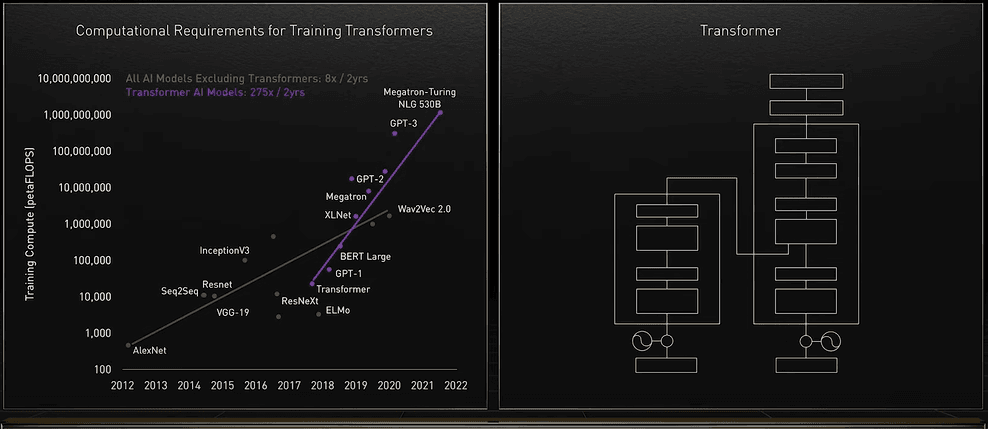
Google BERT for language understanding, NVIDIA MegaMolBart for drug discovery, and DeepMind AlphaFold are all breakthroughs traced to Transformers.

-
NVidia AI

-
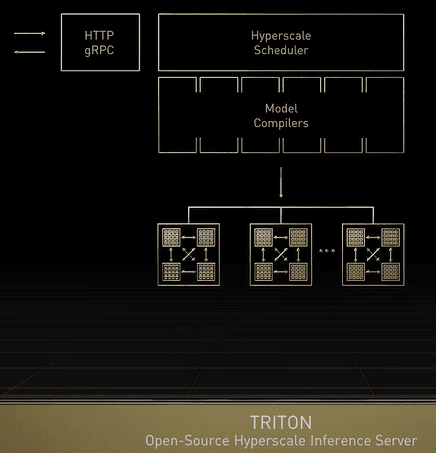
TRITON, Open-Source Hyperscale Inference Server, supports any model – CNNs, RNNs, Transformers, GNN, decision trees, any framework like Tensor Flow, PyTorch, Python, ONNX, XGBoost, supports any query type – real-time, offline, batched, or streaming audio and video, supports all ML platforms – AWS, Azure, Google, Alibaba, VMWare, Domino Data Lab, OctoML, and more.Triton runs in any location – cloud, on-prem, edge, or embedded.
-
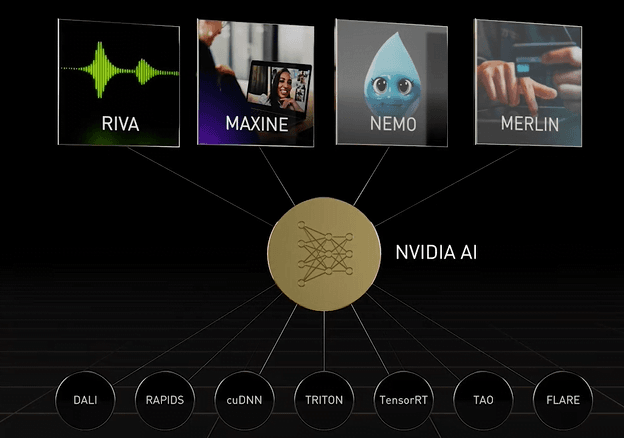
NVIDIA Riva is a state-of-the-art speech AI that is end-to-end based on deep learning.
-
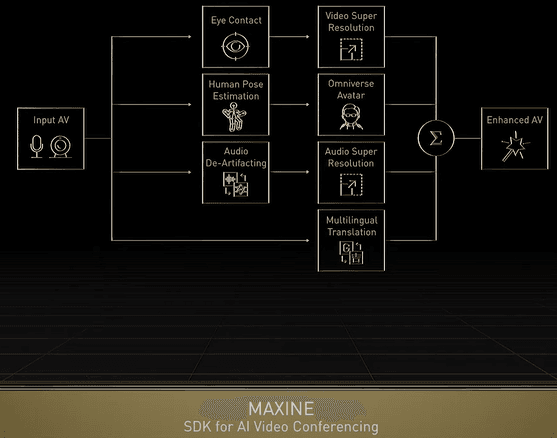
MAXINE is an SDK featuring state-of-the-art AI algorithms for reinventing communications.
神了,这个东西用在视音频会议上,即使你的眼睛没有注视镜头而是在读下方提词器对方看到的却是你的直接眼神接触
-
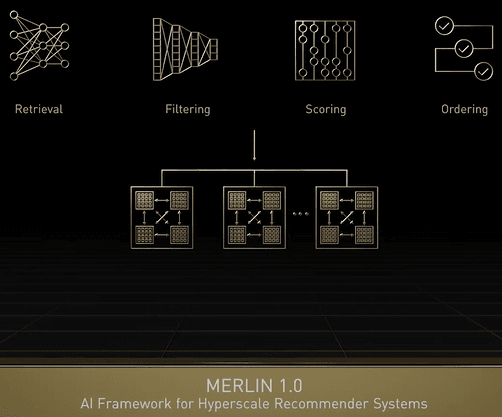
梅林来了,各种推荐的AI框架,腾讯短视频推荐基于此
NVIDIA Merlin is an AI framework for recommender systems.
-
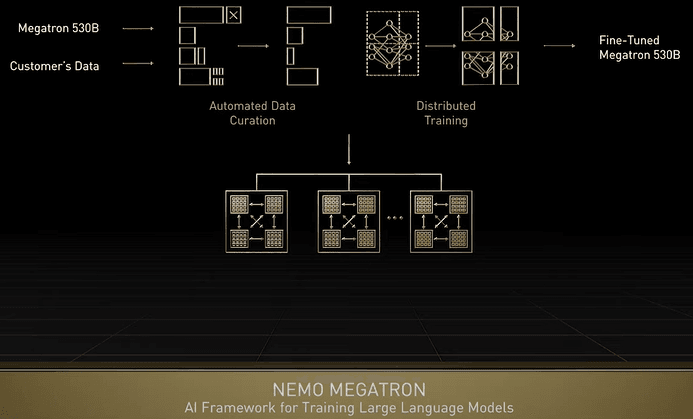
尼莫鱼来了,自然语言处理
Nemo Megatron is a specialized AI framework for training large language models – up to trillions of parameters.
To get the best performance possible on the target infrastructure, Nemo Megatron does automatic data, tensor, and pipeline parallelism, orchestration and scheduling, and auto precision adaptation.

数字生物变革中的术语,完全不懂呢
Oxford Nanopore Gene Sequencer
AI Basecalling
DNA Sequence
RoseTTAFold
Protein 3D Structure
厉害了,来了一个MLOps
New organizations call MLOps are showing up in companies around the world. Their fundamental mission is to efficiently and reliably transform data into predictive models – into intelligence.
H100终于来了,主要参数
800亿个晶体管
TSMC 4N process
4.9TB/s 带宽
基于5代PCI-E接口 GPU
使用HBM3内存 GPU
使用TSMC CoWoS 2.5D封装
集成了稳压器
使用SXM模块
Hopper架构,之前的A100是Ampere架构
先恶补一下概念
什么叫TSMC 4N process?
1种新的Tensor Processing format – FP8
每秒浮点运算次数FLOPS
1 PetaFLOPS(千万亿次) = 1000 Trillion FLOPS
The Hopper Transformer Engine combines a new Tensor Core and software that uses FP8 and FP16 numerical formats, and dynamically processes layers of a Transformer network.
Multi-Tenant infrastructure

Hopper Confidential Computing
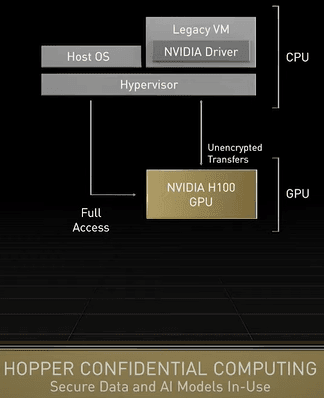
Full VM Isolation with Strong Hardware-Based Security
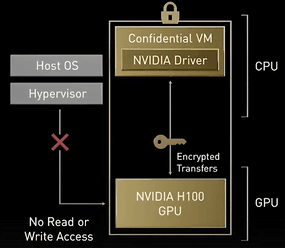
开始拽算法了,需要学习一下
- Floyd-Warshall算法,用于地图的最短路径优化
- Smith-Waterman,基因序列格式匹配
8块H100 SXM模块使用4个NVLINK交换芯片(使用在Mellanox Quantum Infiniband交换机)连接成一个HGX卡,再加上CPU子系统包括2个5代CPU和2个网络模块(每个模块包括4个400Gbps的CX7 IB或以太芯片)就成为了DGX H100 AI计算系统;如果把32个DGX使用NVLINK 交换机连接就成为了H100 DGX POD,其中的每个DGX使用4个光口来连接到NVLINK交换机,每个口有8个100G-PAM4通道承载每秒100GB的数据,32个NVLINK接口连接到1RU的NVLINK交换系统中;多个H100 DGX PODs通过新的Quantum-2 400Gbps的Infiniband交换机连接就成为了DGX SuperPODS;如果使用18个H100 DGX PODs连接就成为了Eos
啥叫SHARP?解答如下: Scalable Hierarchical Aggregation and Reduction Protocol (SHARP)™ technology
老黄接着讲解这么强的GPU怎么部署到主流的服务器上,要点是突破传统架构的瓶颈,即传统的显卡数据要通过CPU交换,除了带来CPU和内存的负荷其中的PCI-E接口是交换的瓶颈。 当然解决方法肯定是RoCE了,旧话题重新将,不过顺势退出了新的H100 CNX倒是挺有意思。他是这么说的:
Moving data in traditional servers’ overloads CPU and system memory and are bottlenecked by PCI-Express.
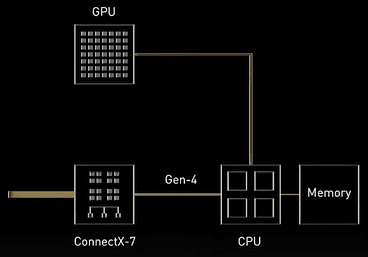
解决方法
The solution is to attach the network directly to the GPU.
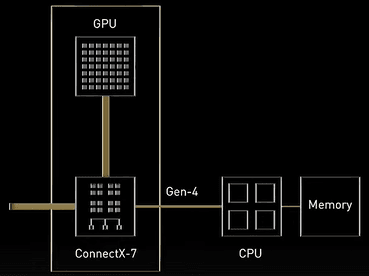
H100 CNX将H100 GPU和CX7放在了一起,同时接口支持PCIe 5,这样数据就可以跳过CPU了。没错的话这块卡内可以直接用400Gbps来互传数据
Data from the network is DMA’d directly to H100 at 50 gigabytes per second and avoids the bottlenecks at the CPU,system memory, and multiple passes across PCI express.

又安利了一下N家的CPU,还起了个女性的名字Grace,还有各种技术的揉搓,CPU加GPU, Grace-Hopper,a single superchip module with direct chip-to-chip connection between the CPU and GPU.
使用了啥技术, 主要是使用NVLINK把处理单元连起来,One of the critical enabling technologies of Grace-Hopper is the memory coherent chip-to-chip NVLINK interconnect
CPU加CPU, Grace Superchip
硬件介绍完来软的了
NVIDIA SDKs with CUDA libraries are the heart and soul of accelerated computing.
首先介绍的是RAPIDS,RAPIDS is a suite of SDKs for data scientists using popular Python APIs for DataFrames, SQL, arrays, machine learning and graph analytics.
然后是cuOpt,就是之前的ReOpt,is an SDK for multi-agent, multi-constraint route planning optimization used for delivery services or autonomous mobile robots inside warehouses.
然后是Graphs, Graphs are one of the most used data structures to represent real-world data, like maps, social networks, the web, proteins and molecules,and financial transactions.
DGL container lets you train large graph neural networks across multiple GPUs and nodes.
Morpheus is a deep learning framework for cybersecurity.
开眼了,与Zero Touch类似还有Zero Trust
cuQuantum is an SDK for accelerating Quantum Circuit Simulators, so researchers can develop quantum computing algorithms of the future that are impossible to explore on quantum computers today.
下面是比较有名的量子计算模拟器框架, Google Cirq, IBM Qiskit, Xanadu’s Pennylane, Quaninuum YKET, and Oak Ridge National Laboratory ExaTN.
Aerial is an SDK for CUDA-accelerated software-defined 5G radio
Sionna, Monai, FLARE
NGC,NVIDIA GPU CLOUD
后面有很大的篇幅是在介绍Omniverse,来自于digital twin,创造一个第二世界,元宇宙
支持其运算的被命名为OVX(和前面的DGX对应),第一代包括8个A40 RTX显卡和3个200Gbps的CX6网口和双Intel Icelake处理器;同样的通过Nvidia Spectrum-3 200G 来连接32个OVX就组成了OVX SuperPOD,同时网络单元和计算单元之间使用PTP同步时间和RDMA来减少传输延迟。LaunchPads
第二代OVX基于Spectrum-4 400G以太网交换机
Omniverse目前包括这几个框架工具,Developer tools,CAD Importers, Deepsearch, Replicator, Omnigraph, Behavior, Animation, Avatar,MODULAR,DRIVE, ISSAC, METROPOLIS, HOLOSCAN
还有自动驾驶硬件套件Hyperion 9,包括14个摄像头,9个雷达,3个激光雷达和20个超声波,不过最早要等到2026年才能从汽车上看到
用自动驾驶来生成地图来训练自动驾驶
lightsheet microscopes来看细胞,使用NVIDIA CLARA HOLOSCAN
Metropolis and Issac,
AMR AUTOMIC MOTOR ROBOT, ISAAC FOR AMRs, 4 major pillars
Nova, Jetson Orin developer kits
铺垫之后发布了Omniverse Cloud,如果是构建实体->虚拟->实体,也挺有意思